



"Building an AI Medical Assistant Part 1: LLama2 Fine-Tuning with Hugging Face Containers, QLoRA and PEFT With WANDB in AWS Sagemaker Spot Instances to cut LLM customization costs.”
🚀 Boost your LLama2 fine-tuning projects to new heights with the power of Hugging Face Transformers and AWS Spot Instances! 💰 Save up to 90% on your fine-tuning customization costs.

I. Introduction
Generative AI is currently gaining a lot of momentum. Modern Large Language Models have the ability to generate relevant responses to human queries. This has motivated many new AI startups to apply this capability to everyday business tasks, automate workflows and processes, and improve work products.

One potential workflow that comes to mind is a clinical conversation between a clinician and a patient. Clinics and medical care providers have existing documentation on these clinical scenarios. Large Language Models are particularly good at this. With anonymized patient conversation data, can we train a Large Language Model to respond to patient questions? How effective will this be? What benefits can modern clinical practice gain from modern Large Language Models?
In part 1 of this newsletter, we cover the data pre-processing and model fine-tuning using QLoRA and Hugging Face PEFT on AWS Sagemaker spot instances and see the resulting cost savings!
In part 2, we will be deploying the fine-tuned llama-2-13b-chat-hf (md-assistant model) to an inference container in AWS Sagemaker and we will build a simple chat user interface to avail the services provided by the new chat model.
Amazon SageMaker Spot Instances, Hugging Face DLC containers, and Weights and Biases API
In this two-part newsletter, we will dive into the use of Amazon SageMaker spot instances, Hugging Face DLC containers, and the Weights and Biases API to fine-tune the LLaMA2-13B-chat-hf model on a patient-clinician conversation dataset. This workflow has potential applications in clinical practice, where Large Language Models can be trained to respond to patient questions as a tool for the clinician. We will discuss the benefits of using SageMaker spot instances, including cost savings and scalability, as well as the advantages of using Hugging Face DLC containers for model deployment. Additionally, we will explore the role of the Weights and Biases API in monitoring and optimizing machine learning experiments.
II. Background
Overview of the chosen model architecture: LLaMA-2-13B-chat-hf
LLaMA2 is a family of pre-trained language models developed by Meta AI, which have gained popularity among researchers and practitioners in natural language processing (NLP) due to their impressive performance across various benchmarks. Additionally, Among the many available variants, we selected the LLaMA2-13B-chat-hf model for our fine-tuning experiment. But why did we choose this particular model?
One of the main reasons behind my choice was the fact that the LLaMA2-13B-chat-hf model has been pre-trained on a diverse range of text data, including conversational datasets like Cornell Movie Dialog Corpus and OpenSubtitles. This pre-training objective allows the model to learn patterns and structures commonly found in human dialogues, making it well-suited for generating coherent and contextually appropriate responses in chatbot scenarios. In other words, the "chat" in the model name reflects its chat question and answer pre-training, which aligns with our goal of developing a conversational AI system for healthcare professionals.
Another important factor was the balance between model size and computational requirements. Compared to smaller models like LLaMA2-7B, the LLaMA2-13B-chat-hf model offers better performance and more capacity to handle complex conversations. However, larger models like LLaMA2-70B come with increased computational demands and longer training times, which could limit our ability to experiment with different hyperparameter configurations within a reasonable time frame. By selecting the mid-sized LLaMA2-13B-chat-hf model, we were able to strike a good balance between these competing factors.
Major factors in choosing LLama 2 models pertaining to licensing.
LLama2 is an open-source implementation of the language model, LLaMA.
The project is released under the Apache License 2.0, which allows for free use, modification, and distribution of the software.
The Apache License 2.0 is a permissive open-source license that allows for free use, modification, and distribution of software.
The license provides a perpetual, world-wide, non-exclusive, no-charge, royalty-free license to use, reproduce, modify, and distribute the software.
LLama2 uses other open-source libraries and frameworks that are released under their own licenses, such as PyTorch (MIT License) and transformers (Apache License 2.0).
The open-source licensing of LLama2 allows for maximum flexibility and freedom for users to use, modify, and distribute the software as they see fit.
The licensing aligns with the goals of the open-source community, which emphasizes collaboration, transparency, and freely available software.
Fine-tuning the model is like doing the fit and finish of the raw material which is the pre-trained model
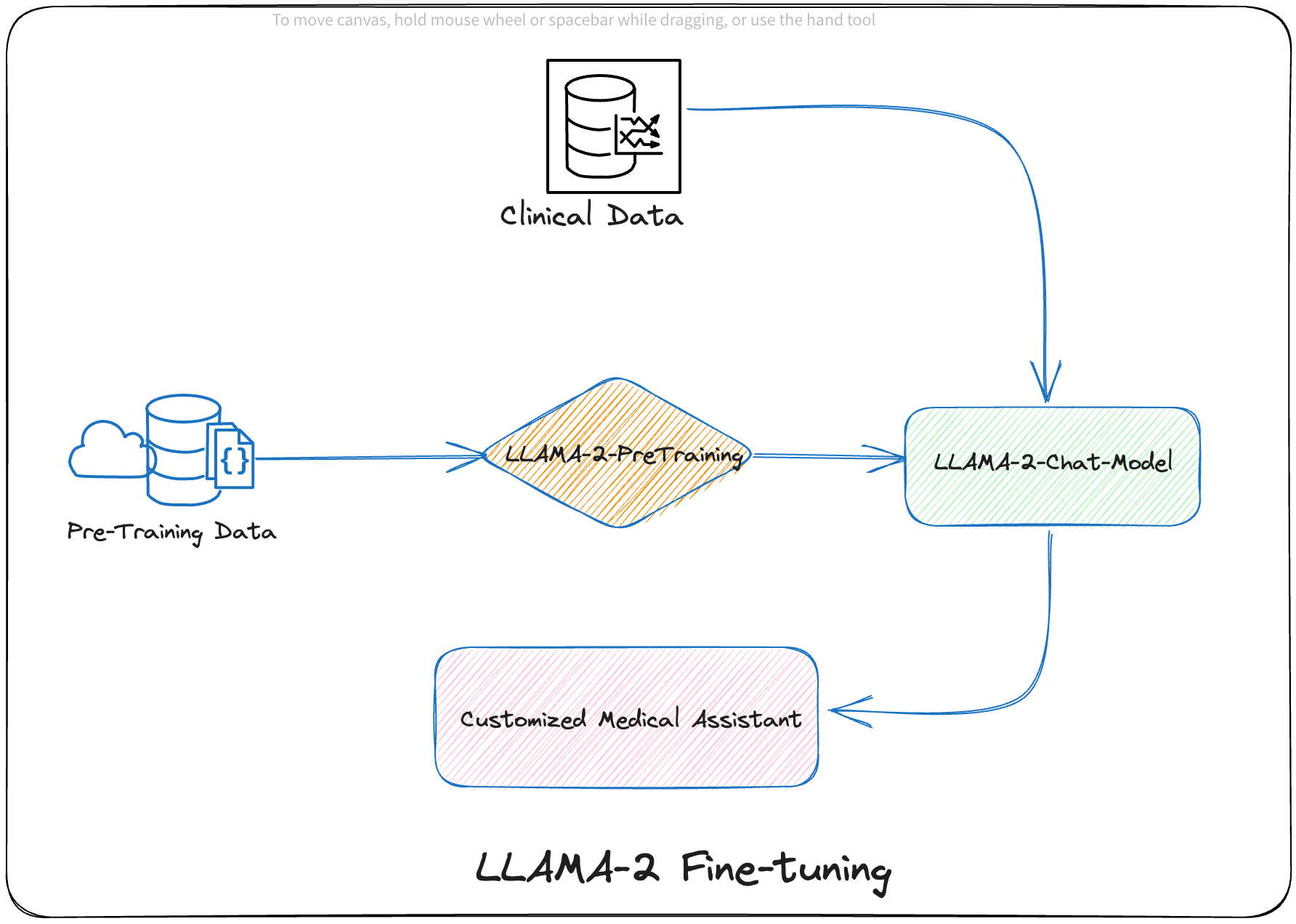
Fine-tuning pre-trained language models for specific domains is crucial for achieving optimal performance in various applications, especially in scenarios where the model needs to understand domain-specific terminology, concepts, and nuances. In the context of patient-clinician conversations, fine-tuning a pre-trained language model can significantly improve its ability to comprehend medical jargon, diagnose diseases, and provide relevant treatment recommendations. In essence, the pre-trained model is the raw material and fine-tuning the model is the process of carving and shaping the raw material into a beautiful piece of sculpture!
Here are some reasons why fine-tuning pre-trained language models is important for specific domains like patient-clinician conversations:
Domain-specific vocabulary: Medical conversations often involve specialized terminology that may not be present in general language datasets. By fine-tuning a pre-trained model on a dataset containing medical terms and phrases commonly used in patient-clinician interactions, the model becomes more adept at understanding the unique vocabulary associated with this domain.
Concept drift: The underlying distribution of data in different domains can differ significantly, leading to a phenomenon known as concept drift. Fine-tuning a pre-trained model helps adapt it to the new domain, ensuring that it can capture subtle variations in language usage, sentiment, and topics that are specific to patient-clinician conversations.
Contextual understanding: Patient-clinician conversations often involve complex dialogues that require an understanding of the context, including the patient's medical history, symptoms, and treatment plans. Fine-tuning a pre-trained model enables it to better grasp the relationships between these elements and provide more accurate responses.
Personalization: Every patient's situation is unique, and clinicians must consider individual factors when making decisions about diagnosis and treatment. By fine-tuning a language model on a dataset that reflects the diversity of patients and clinicians, the model can learn to recognize patterns and tailor its responses to suit each person's needs. Think about the correlations that the LLM can point out in a particular patient’s history.
Ethical considerations: Healthcare is a sensitive domain, and there are ethical concerns surrounding the use of AI in patient care. Fine-tuning a pre-trained model on a dataset that adheres to privacy regulations and respects patient autonomy helps ensure that the model's responses align with ethical principles and standards.
Improved accuracy: Fine-tuning a pre-trained model typically leads to improved accuracy compared to using a generic, pre-trained model. This is because the model has learned to recognize patterns and relationships specific to the target domain, resulting in fewer errors and more effective communication.
Efficient use of resources: Fine-tuning a pre-trained model requires less data and computational resources than training a model from scratch. By leveraging the knowledge captured by the pre-trained model, we can adapt it to the target domain more efficiently and effectively.
Faster adaptation to new tasks: Once a pre-trained model has been fine-tuned for a specific domain, it can quickly adapt to new tasks within that domain. This is particularly useful in healthcare, where new treatments, technologies, and regulations emerge regularly, and the model needs to be able to respond accordingly.
Enhanced interpretability: Fine-tuning a pre-trained model can help make its internal workings more transparent and interpretable. By analyzing the model's weights and activations, we can gain insights into how it processes domain-specific language and which features it deems most important.
Better handling of out-of-distribution inputs: Fine-tuning a pre-trained model improves its ability to handle unexpected or out-of-distribution inputs that may arise in real-world applications. This is critical in healthcare, where unusual cases or unforeseen situations can have significant consequences.
So, fine-tuning pre-trained language models for specific domains like patient-clinician conversations is essential for achieving high accuracy, efficiency, and ethical considerations. By adapting these models to the unique characteristics of the target domain, we can develop more effective and reliable AI language models that support clinicians in providing better patient care.
III. System Design
Pre-requisites (Disclaimer: I am not sponsored by any of these companies. I am a paid subscriber to AWS, Weights & Biases and Hugging Face)
AWS Account:
Cloud Computing Services - Amazon Web Services (AWS)
HuggingFace Account: Free signup
Weights & Biases Account: Free signup
W&B Docs | Weights & Biases Documentation
Meta LLama-2 approval for access:
Llama access request form - Meta AI
Amazon SageMaker and its benefits for machine learning and AI development
With AWS SageMaker, the process of fine-tuning a pre-trained language model (LLM) becomes significantly simpler and more efficient for machine learning engineers. By leveraging the cloud infrastructure provided by SageMaker, engineers can focus solely on the fine-tuning task without worrying about the underlying infrastructure.
Here are some ways in which SageMaker streamlines the LLM fine-tuning process:
No Infrastructure Setup: SageMaker eliminates the need for engineers to perform low level set up and manage infrastructure, such as spinning up containers, managing data storage, and configuring network security. This saves time and effort, allowing engineers to focus on the core task of fine-tuning the LLM.
Easy Access to Data: SageMaker provides integrated data management capabilities, making it easy for engineers to access and manipulate data for fine-tuning. This includes data loading, preprocessing, and feature engineering, all of which can be performed within the SageMaker framework.
Automated Hyperparameter Tuning: SageMaker automates the hyperparameter tuning process, allowing engineers to focus on other aspects of the fine-tuning task. This feature saves time and reduces the risk of overfitting or underfitting the model.
Support for Various Frameworks: SageMaker supports a variety of machine learning frameworks, including TensorFlow, PyTorch, and Scikit-learn. This means that engineers can use their preferred framework for LLM fine-tuning, further simplifying the process.
Flexible Deployment Options: Once the fine-tuning process is complete, SageMaker provides flexible deployment options, including hosting the model in a SageMaker endpoint, deploying it to AWS Lambda, or exporting it to a containerized application. This enables engineers to easily integrate the fine-tuned LLM into their desired environment.
Time Savings: By leveraging SageMaker's automated infrastructure provisioning, data management, and hyperparameter tuning capabilities, engineers can save a significant amount of time compared to setting up and managing the infrastructure themselves. This allows them to focus on the fine-tuning task at hand and deliver high-quality LLM models more rapidly.
Improved Productivity: With SageMaker, engineers can work more efficiently and avoid tedious, repetitive tasks. They can focus on developing and refining their LLM models, leading to improved productivity and better model performance.
Better Collaboration: SageMaker facilitates collaboration among team members, enabling them to work together more effectively. Features like version control, reproducibility, and shared notebooks simplify the collaborative fine-tuning process, ensuring that everyone is on the same page.
Cost Optimization: SageMaker provides optimized computing resources that adjust to meet changing demand. This means that engineers can minimize costs associated with LLM fine-tuning while still achieving optimal results.
Security and Compliance: SageMaker adheres to strict security and compliance standards, giving engineers peace of mind regarding data privacy and protection. This allows them to focus on the fine-tuning task without worrying about potential security breaches or non-compliance issues.
By using AWS SageMaker for LLM fine-tuning, machine learning engineers can offload the burden of managing infrastructure and focus exclusively on optimizing their models. This leads to increased productivity, simplified collaboration, reduced costs, and improved model performance, ultimately resulting in better outcomes for their organization.
Introduction to Hugging Face DLC containers and their integration with SageMaker
HuggingFace DLC (Deep Learning Container) is a containerization technology specifically designed for deep learning models. It provides a simple and efficient way to package and distribute deep learning models and their dependencies, allowing developers to focus on building models instead of managing infrastructure.
DLCs are built on top of Docker and provide a standardized way to package models, datasets, and other dependencies required for training and inference. They support a wide range of deep learning frameworks, including TensorFlow, PyTorch, and Keras.
SageMaker, on the other hand, is a fully managed service provided by Amazon Web Services (AWS) that makes it easy to build, train, and deploy machine learning models at scale. It provides a variety of features, including automatic model tuning, hyperparameter optimization, and deployment of models to production environments.
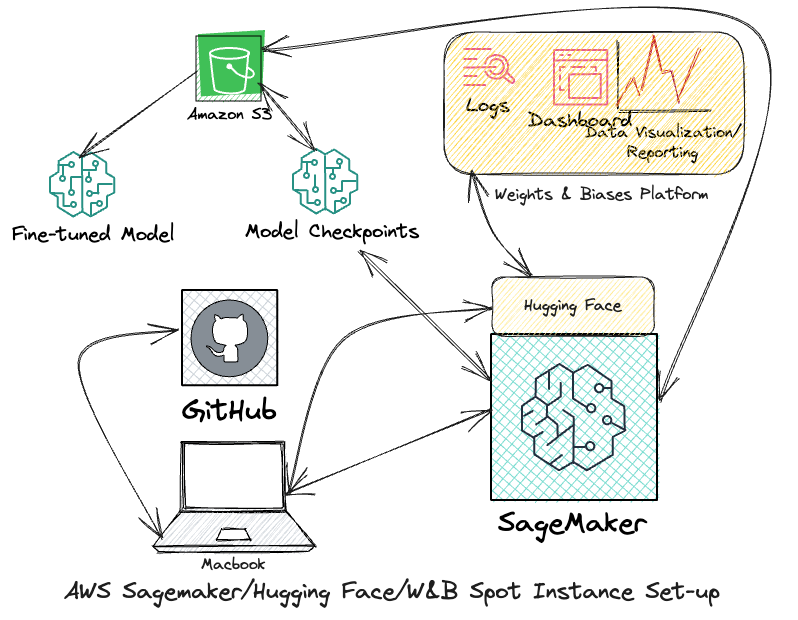
Advantages of integrating Hugging Face DLCs with SageMaker
Simplified model packaging: Hugging Face DLCs provide a standardized way to package models and their dependencies, making it easy to manage and distribute models across different environments.
Faster model deployment: By using DLCs, you can quickly deploy models to SageMaker, reducing the time and effort required to set up and configure environments.
Improved reproducibility: DLCs ensure that models are trained and deployed consistently across different environments, which improves reproducibility and reduces the risk of errors caused by inconsistent environments.
Easier collaboration: DLCs make it easier for data scientists to collaborate on projects by providing a standardized way to exchange models and reproduce experiments.
Better resource utilization: SageMaker's integration with DLCs allows you to take advantage of spot instances and other cost-effective compute resources, reducing the cost of training and deploying models.
Fine-tuning Set-up:
When leveraging the MedDialog dataset to fine-tune a pre-trained LLaMA-2-13B-chat-hf model, there are several key considerations to keep in mind to ensure optimal performance and efficiency.
First and foremost, it is crucial to select an appropriate batch size for training. In this case, a batch size of 2 per device is recommended to strike a balance between resource utilization and training speed. By doing so, the model can be trained efficiently without sacrificing too much time or computational resources.
Next, the number of epochs must be carefully chosen. In this scenario, running the experiment for 3 epochs should suffice for the model to converge properly and achieve satisfactory results. Selecting the right number of epochs is critical, as it impacts both the accuracy of the model and the time required for training.
AdamW optimization is also vital for achieving optimal model performance. AdamW is a well-known algorithm that adapts the learning rate for each parameter individually, based on the magnitude of the gradient. This helps to prevent overshooting or undershooting the optimal learning rate, resulting in faster convergence and better model accuracy.
Another important aspect to consider is the choice of instance type. For this particular use case, an ml.g5.4xlarge SageMaker spot instance is recommended. Not only does this instance type offer powerful GPU acceleration, but it also comes with a discounted pricing model thanks to Amazon Elastic Compute Cloud (EC2) Spot Instances. By leveraging EC2 Spot Instances, SageMaker can automatically handle bid management and instance selection, streamlining the process and minimizing costs.
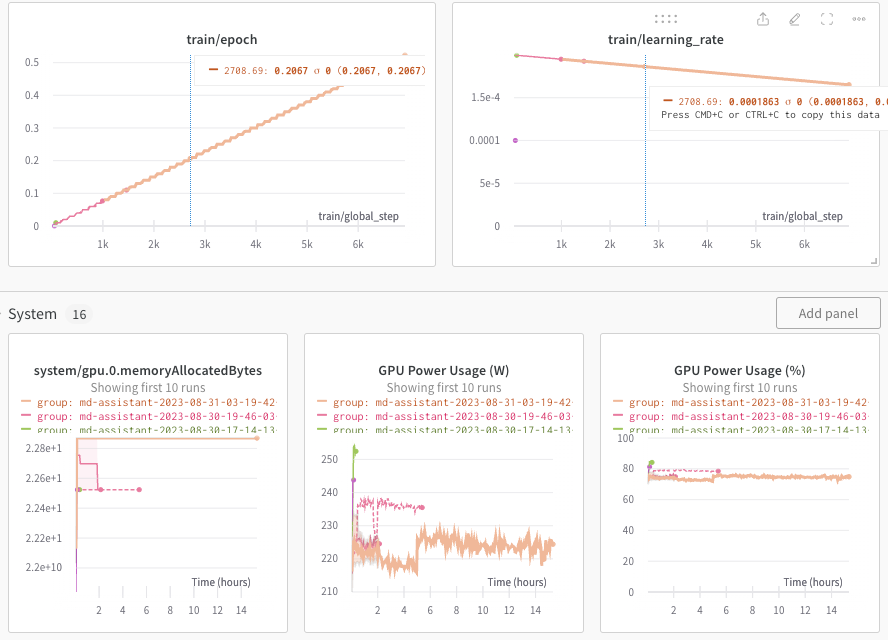
Monitoring the fine-tuning progress is equally important. From the smart folks at Weights & Biases ( https://wand.ai), the wandb API provides comprehensive monitoring capabilities for SageMaker/HuggingFace experiments, including essential metrics like loss, accuracy, and validation accuracy. Real-time monitoring enables engineers to identify potential issues early on and make informed decisions throughout the experiment. Additionally, it lets you version and iterate on datasets, evaluate model performance, reproduce models, visualize results and spot regressions, and share findings with colleagues.
In the fine-tuning process (run_clm.py), I simply imported wandb and using my api key, logged-in to the wandb.ai platform within my training script. By adding the following to the python script, this was made possible. Pretty simple and you can view the real-time progress as shown below. The different colors represent different traces post spot instance interruption. Yes it remembers the last trace and depicts the newer trace in a different color!
# making
import wandb
.
.
.
.
# login to wandb instrumentation platform
if args.wandb_api_key:
print(f'logging in to wandb.....')
wandb.login(anonymous='never', key=args.wandb_api_key)
.
.
.
# add report_to='wandb'parameter
# Define training args
output_dir = args.output_dir
training_args = TrainingArguments(
output_dir=output_dir,
resume_from_checkpoint=True,
overwrite_output_dir=True,
per_device_train_batch_size=args.per_device_train_batch_size,
bf16=args.bf16, # Use BF16 if available
learning_rate=args.lr,
num_train_epochs=args.epochs,
gradient_checkpointing=args.gradient_checkpointing,
# logging strategies
logging_dir=f"{output_dir}/logs",
logging_strategy="steps",
logging_steps=10,
#warmup_steps=100,
save_steps=50,
save_strategy="steps",
report_to="wandb",
run_name=f'md-asistant-{time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())}'
)
Finally, it's worth noting that using spot instances has its advantages over on-demand instances. Besides being significantly cheaper, spot instances grant access to a larger pool of available instances, making it easier to launch experiments promptly. Additionally, spot instances allow for greater flexibility in scaling resources up or down according to changing demands. Of course, there are some risks associated with spot instances, such as potential instance termination due to fluctuations in EC2 spot instance supply and demand. Nevertheless, SageMaker's integration with EC2 Spot Instances mitigates these risks while maximizing the benefits.
By taking these factors into account when fine-tuning the LLaMA-2-13B-chat-hf model on the MedDialog dataset, experienced ML engineers can create a robust and cost-efficient chatbot solution that delivers high-quality user experiences while optimizing resource utilization.
Dataset: description of the patient-clinician conversation dataset used for fine-tuning
First introduced in a 2004 paper by Xuehai He et al., MedDialog consists of two large-scale medical dialogue datasets that capture conversations between patients and doctors across various medical domains.
What makes MedDialog particularly interesting for business applications is its scope and diversity. The dataset contains over 250,000 utterances from both patients and doctors, spanning 51 different medical categories and 96 specialties. This wealth of information provides a unique opportunity for machine learning models to learn patterns and relationships within medical dialogues, which can ultimately enhance decision-making processes in healthcare settings.
Developing conversational AI systems that can facilitate patient-doctor interactions using clinic or provider specific dialog datasets is a valid use case. By analyzing the language used in medical consultations, these systems can better understand patient concerns and provide personalized recommendations for treatment options. This not only improves patient satisfaction but also streamlines the consultation process for doctors, allowing them to focus on more complex cases.
MedDialog Dataset Preprocessing
The code provided (modified from https://github.com/philschmid/sagemaker-huggingface-llama-2-samples) is responsible for formatting medical dialog data into a suitable format for training a language model. Here's an overview of the steps involved in this process:
Loading the Data: The first step is to load the medical dialog data from a dataset file. This is done using the
load_datasetfunction, which returns a pandas dataframe containing the data.Removing Unwanted Columns: The next step is to remove any unwanted columns from the dataframe. In this case, we only need the "text" column, so we remove all other columns using the
remove_columnsparameter of thedf.map()method.Formatting Samples: We then apply a custom function called
template_datasetto each row of the dataframe. This function takes a sample and formats it according to the required format for our language model. Specifically, it adds a system prompt and user prompt to each sample, separated by a newline character.Chunking and Tokenizing: After formatting the samples, we use another custom function called
chunkto split the text into smaller chunks. Each chunk has a maximum length of 2048 tokens. Any remaining tokens are saved as a global variable calledremainderto be used in the next batch. Within each chunk, we also tokenize the text using thetokenizerfunction.Preparing Labels: Once we have our chunks of text, we create labels for them. The labels are simply copies of the input IDs.
Saving the Data: Finally, we save the processed data to disk using the
save_to_diskmethod. The output path is specified using thetraining_input_pathvariable which is an s3 bucket.
The code loads medical dialog data, removes unnecessary columns, formats each sample with system and user prompts, chunks and tokenizes the text, prepares labels, and saves the processed data to disk. These steps are necessary to prepare the data for training a language model capable of generating appropriate responses to medical queries.
######################################################
# Pre-processing of medical_dialog dataset from hf hub.
# Stores formatted, tokenized, chunked
# training data to s3 bucket.
# Derived from @philschmid hugginface-llama-2-samples
# on a different hf dataset
######################################################
import sagemaker
import boto3
from random import randint
from itertools import chain
from functools import partial
from datasets import load_dataset
from random import randrange
import json
import pandas as pd
from transformers import AutoTokenizer
#sagemaker_session_bucket='mlpipes-sm' # us-west-2
sagemaker_session_bucket='mlpipes-03-29-2023-asabay' # us-east-1
role_name = 'Sagemaker-mle'
dataset_name = 'medical_dialog'
dataset_lang = 'en'
model_id = 'meta-llama/Llama-2-13b-chat-hf'
# empty list to save remainder from batches to use in next batch
remainder = {"input_ids": [], "attention_mask": [], "token_type_ids": []}
# sess = sagemaker.Session()
# fetch tokenizer pad_token
def fetch_tokenizer(model_id):
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
return tokenizer
tokenizer = fetch_tokenizer(model_id)
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
def init_sagemaker(role, session_bucket):
if session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName=role_name)['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
return (sess, role)
# load dataset and remove un-used fields
def load_and_extract(dataset_name, dataset_lang):
dataset = load_dataset(dataset_name, dataset_lang)
dataset = dataset['train'].remove_columns(['file_name', 'dialogue_id', 'dialogue_url'])
return dataset
# function to format samples to llama-2-chat-hf format
# which is:
# <s>[INST] <<SYS>>
# System prompt
# <</SYS>>
# User prompt [/INST] Model answer </s>
def format_dialogue(sample):
instruction = f"[INST]{sample['dialogue_turns']['utterance'][0]}[/INST]"
response = f"{sample['dialogue_turns']['utterance'][1]}"
# join all the parts together
prompt = "\\n".join([i for i in [instruction, response] if i is not None])
return '<s>' + prompt + '</s>'
# template dataset to add prompt to each sample
def template_dataset(sample):
sample["text"] = f"{format_dialogue(sample)}{tokenizer.eos_token}"
return sample
# chunk and tokenize
def chunk(sample, chunk_length=2048):
# define global remainder variable to save remainder from batches to use in next batch
global remainder
# Concatenate all texts and add remainder from previous batch
concatenated_examples = {k: list(chain(*sample[k])) for k in sample.keys()}
concatenated_examples = {k: remainder[k] + concatenated_examples[k] for k in concatenated_examples.keys()}
# get total number of tokens for batch
batch_total_length = len(concatenated_examples[list(sample.keys())[0]])
# get max number of chunks for batch
if batch_total_length >= chunk_length:
batch_chunk_length = (batch_total_length // chunk_length) * chunk_length
# Split by chunks of max_len.
result = {
k: [t[i : i + chunk_length] for i in range(0, batch_chunk_length, chunk_length)]
for k, t in concatenated_examples.items()
}
# add remainder to global variable for next batch
remainder = {k: concatenated_examples[k][batch_chunk_length:] for k in concatenated_examples.keys()}
# prepare labels
result["labels"] = result["input_ids"].copy()
return result
def process_data():
sm_session, _ = init_sagemaker(role_name, sagemaker_session_bucket)
ds = load_and_extract(dataset_name, dataset_lang)
ds = ds.map(template_dataset)
print(ds[randint(0, len(ds))]["text"]) # print random sample
lm_dataset = ds.map(
lambda sample: tokenizer(sample["text"]), batched=True, remove_columns=list(ds.features)
).map(partial(chunk, chunk_length=2048),
batched=True,
)
print(f"Total number of samples: {len(lm_dataset)}")
# save train_dataset to s3
training_input_path = f's3://{sm_session.default_bucket()}/processed/llama/md_dialouge/train'
lm_dataset.save_to_disk(training_input_path)
print("uploaded data to:")
print(f"training dataset to: {training_input_path}")
if __name__ == '__main__':
process_data()
Fine-Tuning with QLora and PEFT for Cost Savings
As a way to reduce training costs on AWS Sagemaker, the QLoRA method was used. This would allow the use of smaller GPU instances which in this case is a single GPU ml.g5.4xlarge sagemaker spot training instance (16 cvpu, 64G mem, 1 gpu, 24G total gpu mem, A10G). The on-demand cost in aws us-east-1 region is $2.03 per hour, discounted by up to 90% if using spot instances. In this project, the discount is around 65% using this setup.
QLoRA (Quantized LORA) is a novel method for efficient finetuning of quantized large language models (LLMs) proposed by Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer in their research paper titled "QLORA: Efficient Finetuning of Quantized LLMs." The authors present a systematic approach to fine-tune quantized LLMs for downstream natural language processing tasks while maintaining competitive performance and reducing computational requirements.
The authors address the challenge of finetuning large language models that have been quantized, which results in loss of precision and degraded performance. They propose QLoRA, which leverages the strengths of two existing techniques: LORA (Latent Optimization Regularization Algorithm) and quantization. QLoRA introduces a regularization term that encourages the model to learn discrete representations that are close to the original continuous representations. This term is combined with the standard cross-entropy loss, resulting in a hybrid objective function that enables efficient finetuning of quantized LLMs.
The authors evaluate QLoRA on several benchmark datasets and compare its performance to full-precision and quantized baselines. Their results show that QLoRA achieves competitive performance with the full-precision baseline while providing significant computational savings. Specifically, they report that QLoRA achieves 97% of the full-precision performance on the GLUE benchmark while being 3.8x more computationally efficient.
The authors also investigate the effectiveness of QLoRA across different levels of quantization and observe that it consistently outperforms the quantized baseline across all levels. Furthermore, they demonstrate that QLoRA can be used for few-shot learning, adapting the model to new tasks with only a handful of labeled examples.
In the training script, the llama2 model is instantiated with quantization_config parameter passed in as a BitsAndBytesConfig object that specifies:
# from <https://github.com/philschmid/sagemaker-huggingface-llama-2-samples>, run_clm.py
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
args.model_id,
use_cache=False
if args.gradient_checkpointing
else True, # this is needed for gradient checkpointing
device_map="auto",
quantization_config=bnb_config,
)
Further, PEFT is implemented to strike a middle ground between full-fine tuning which is resource intensive, and feature engineering. Parameter-Efficient Fine-Tuning (PEFT) is a novel approach to adapting pre-trained language models (PLMs) to various downstream tasks without fine-tuning all model parameters. PEFT selectively updates a small number of extra parameters, striking a balance between performance and efficiency. Recent advancements in PEFT techniques have achieved performance comparable to full fine-tuning while significantly reducing computational and storage costs. PEFT offers a promising solution for scaling up NLP models while minimizing resource requirements, making it a valuable tool in shaping the future of natural language processing, particularly in resource-constrained scenarios.
The PEFT setup is done below:
# from <https://github.com/philschmid/sagemaker-huggingface-llama-2-samples>, run_clm.py
def create_peft_model(model, gradient_checkpointing=True, bf16=True):
from peft import (
get_peft_model,
LoraConfig,
TaskType,
prepare_model_for_kbit_training,
)
from peft.tuners.lora import LoraLayer
# prepare int-4 model for training
model = prepare_model_for_kbit_training(
model, use_gradient_checkpointing=gradient_checkpointing
)
if gradient_checkpointing:
model.gradient_checkpointing_enable()
# get lora target modules
modules = find_all_linear_names(model)
print(f"Found {len(modules)} modules to quantize: {modules}")
peft_config = LoraConfig(
r=64,
lora_alpha=16,
target_modules=modules,
lora_dropout=0.1,
bias="none",
task_type=TaskType.CAUSAL_LM,
)
model = get_peft_model(model, peft_config)
Finally, the entire training_function prepares a llama-2-13b-chat-hf model with QLora and PEFT set-up parameters for fine-tuning as shown before trainer.train() is called. By the way, you will also see how this training script checks if it is recovering from a spot instance or a user stop interruption by checking for the last_checkpoint. In the TrainingArguments object instantiation prior to the Trainer object instantiation, you can see the parameters required for spot instance training. Checkpointing is enabled by setting save_strategy as “steps” and save_steps=10 sets a checkpoint every 10 steps to the s:3// checkpoint location. This is how training recovery is made possible. See code below:
# modified from <https://github.com/philschmid/sagemaker-huggingface-llama-2-samples>
def training_function(args):
# set seed
set_seed(args.seed)
dataset = load_from_disk(args.dataset_path)
# load model from the hub with a bnb config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
args.model_id,
use_cache=False
if args.gradient_checkpointing
else True, # this is needed for gradient checkpointing
device_map="auto",
quantization_config=bnb_config,
)
# create peft config
model = create_peft_model(
model, gradient_checkpointing=args.gradient_checkpointing, bf16=args.bf16
)
# Define training args
output_dir = args.output_dir
training_args = TrainingArguments(
output_dir=output_dir,
resume_from_checkpoint=True,
overwrite_output_dir=True,
per_device_train_batch_size=args.per_device_train_batch_size,
bf16=args.bf16, # Use BF16 if available
learning_rate=args.lr,
num_train_epochs=args.epochs,
gradient_checkpointing=args.gradient_checkpointing,
# logging strategies
logging_dir=f"{output_dir}/logs",
logging_strategy="steps",
logging_steps=10,
#warmup_steps=100,
save_steps=50,
save_strategy="steps",
report_to="wandb",
run_name=f'md-asistant-{time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())}'
)
# Create Trainer instance
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=default_data_collator,
)
# check if checkpoint exists. if so continue training from where we left off,
# this is only for spot instances
if get_last_checkpoint(args.output_dir) is not None:
logger.info("***** continue training *****")
last_checkpoint = get_last_checkpoint(args.output_dir)
print(f'**********got last checkpoint = {last_checkpoint}**********************')
trainer.train(resume_from_checkpoint=last_checkpoint)
else:
print('!!!!!!!!!!!!!!INITIAL TRAINING RUN!!!!!!!!!!!!!!!!!!!!')
trainer.train() # no checkpoints found
sagemaker_save_dir="/opt/ml/model/" # local container directory
if args.merge_weights:
# merge adapter weights with base model and save
# save int 4 model
trainer.model.save_pretrained(output_dir, safe_serialization=False)
# clear memory
del model
del trainer
torch.cuda.empty_cache()
# load PEFT model in fp16
model = AutoPeftModelForCausalLM.from_pretrained(
output_dir,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
)
# Merge LoRA and base model and save
model = model.merge_and_unload()
model.save_pretrained(
sagemaker_save_dir, safe_serialization=True, max_shard_size="2GB"
)
else:
trainer.model.save_pretrained(
sagemaker_save_dir, safe_serialization=True
)
# save tokenizer for easy inference
tokenizer = AutoTokenizer.from_pretrained(args.model_id)
tokenizer.save_pretrained(sagemaker_save_dir)
IV. Results
Fine-tuning traces on Weights & Biases platform.
http://wandb.ai
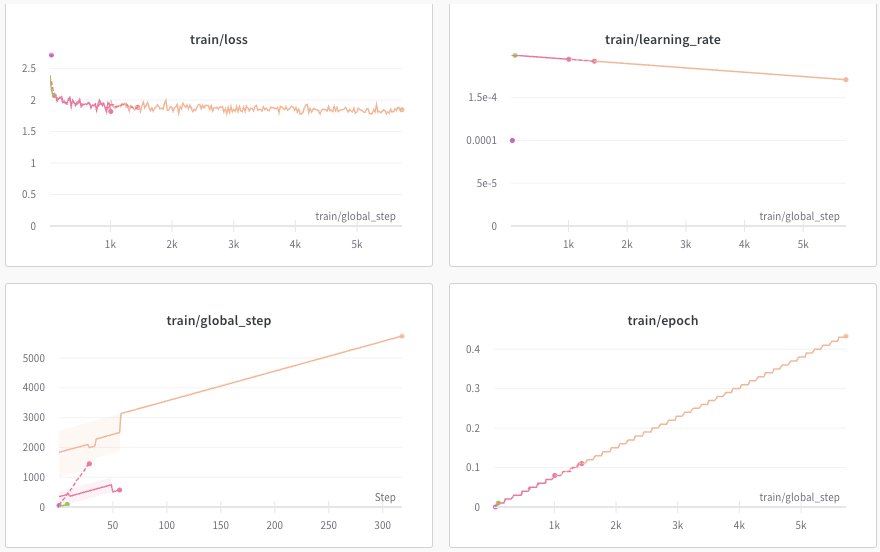
Model cost performance: How much did I save?
Table 1: On-demand versus Spot Instance cost on ml.g5.4xlarge

As can be seen in Table 1, using a small single GPU instance will take longer (147hrs in 3 epochs) to train with a spot instance discounted cost of $104.44. The total cost of using an on-demand instance would be $298.41 versus $104.44 for the entire fine-tuning cycle. This is a modest dataset size that without using QLoRA, PEFT, and Spot Instances could have fine-tuning costs exceeding a thousand dollars. Depending on the resources and time available, we have to balance cost time, and accuracy to deliver the best product possible. In part 2 I plan to make trial runs with larger aws sagemaker instances to compare cost and time and perhaps identify a sweet spot for cost efficiency. In the meantime, we can see very significant fine-tuning cost savings by using QLoRA, PEFT, and AWS Spot Instances.
I encourage you to explore and try different LLM fine-tuning setups using this newsletter article and find what works for you and share your experiences as we learn from each other.
In part 2 of this newsletter article, we will analyze and test the tuned model, deploy it to an inference instance, and build a chat UI for you to try😀
VI. References
All code in this project can be found here.
QLoRA: Efficient Finetuning of Quantized LLMs
MedDialog: Two Large-scale Medical Dialogue Datasets
Philschmid Blog on Spot Instances and Hugging Face Transformers
Philschmid Github on Sagemaker-HuggingFace llama-2 fine-tuning and deployment