



Unraveling the Hidden Magic of Vector Databases 🔍✨
A simple example of how Vector Databases work behind the scenes in a Movie Recommender.

Introduction:
Today, I'm thrilled to share the transformative potential of vector databases in the realm of data-driven decision making. Over the years, I've witnessed how businesses have harnessed the full potential of analytics, and vector databases have emerged as a game-changer, revolutionizing AI and ML architectures. Today, I'm excited to take you on a journey to explore how this cutting-edge technology can be applied in a real-world scenario: a Movie Recommender system, similar to what powers personalized recommendations on platforms like Netflix or Prime Video.
How Vector Databases Drive Personalized Movie Recommendations:
In our Python code example, I'll showcase the seamless integration of Faiss, a powerful vector database from Meta, to create a sophisticated Movie Recommender. By leveraging Faiss alongside Word2Vec embeddings, I'll demonstrate how this technology powers accurate and efficient similarity searches based on movie preferences. This innovative approach enables streaming platforms to offer users a highly personalized and engaging movie-watching experience.
Unlocking the Secrets of Faiss in Movie Recommendations:
Through the code example, I'll reveal how Faiss efficiently organizes and indexes movie vectors, ensuring rapid retrieval of the most relevant movie recommendations for each user. By combining the power of vector databases with state-of-the-art AI algorithms, this system elevates the movie discovery process, enticing users to explore new genres and undiscovered gems.
Join me as we dive into the Python code, where you'll witness firsthand the incredible capabilities of vector databases in action. Let's embark on this exciting journey together to unravel the power of vector databases and their potential to revolutionize your data-driven endeavors, just like the Movie Recommender we're about to unveil.
How the Recommendation System Works
Let me walk you through the technology behind our movie recommendation system. At the core of this system are Word2Vec ( here I’m using the gensim python library, it’s super fast ) embeddings, a powerful technique that represents movie titles as dense vectors in a high-dimensional space. This enables the system to capture semantic relationships between movies, facilitating efficient comparison and similarity calculations.
Word2Vec uses a neural network to learn word embeddings from vast amounts of textual data, such as movie titles in our case. Each word is mapped to a dense vector, where similar words are placed closer together in the vector space. This linguistic context allows us to establish connections between movie titles, even those that may not share identical words but are conceptually related.
To show how these similarity searches work, let’s use Faiss, a remarkable vector database from Meta ( though there are many to choose from such as Pinecone, Milvus, Weaviate etc ). Faiss optimizes the organization and indexing of movie vectors, enabling us to find similar movies rapidly based on user input. By employing Faiss alongside Word2Vec embeddings, we achieve lightning-fast response times, providing users with an exceptional movie discovery experience.
Now that we understand the technology behind our recommendation system, let's dive into it!
Building the Recommendation System
I ran this example python code on AWS Sagemaker with a ml.g4dn.2xlarge single GPU notebook instance with 32 GiB of memory, but you should be able to run this on a local machine preferably with a GPU. I opted to use the Kaggle TMDB 3000+ Movie Dataset-2023 .
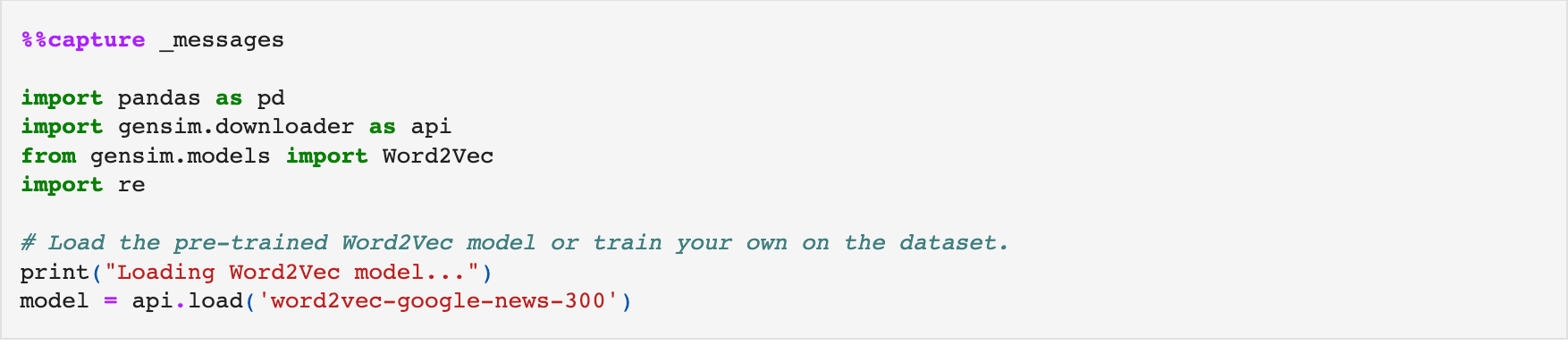
Loading Word2Vec Model and Dataset: We start by importing necessary libraries, capturing messages (output), and loading a pre-trained Word2Vec model from the gensim library.
Preprocessing Text Data: The 'Movie_Name' column in the dataset contains movie titles that need to be preprocessed before using them as input to the Word2Vec model. The function preprocess_text is removes non-alphanumeric characters and convert the text to lowercase. The cleaned movie titles are then stored in a new column called 'title_cleaned' as shown here.

Creating Item Vectors: The function item_name_to_vector converts movie titles to their vector representations using the Word2Vec model. For each movie in the dataset, a dictionary 'item_vectors' is created, where the key is the movie title, and the value is its corresponding vector. Movie titles not found in the Word2Vec vocabulary are excluded from the 'item_vectors' dictionary.

Setting up Faiss Index: The 'item_vectors' are then converted to a NumPy array, which is used to initialize a Faiss index with L2 (Euclidean) distance metric. The item vectors are added to the Faiss index, and the index is saved to a file for future use.

Shown below is a partial output of the print statement above showing the curated vector items. We will use some of these vector “items” later to represent user preference data collected from user interaction.

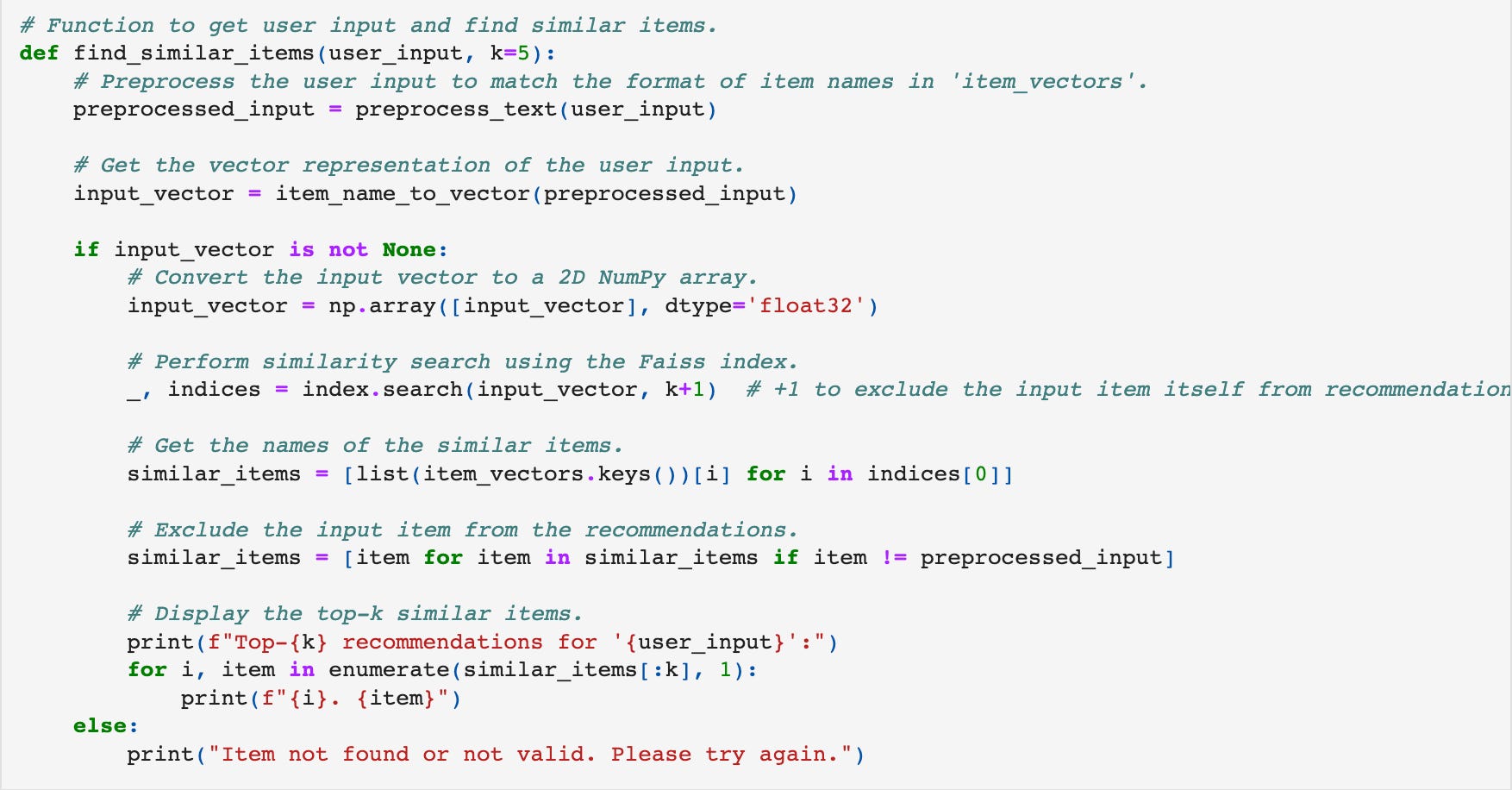
Getting Similar Movie Recommendations: A function called find_similar_items is defined to get similar movie recommendations based on user input. Users can input their preferences or interests, and the function uses Faiss to find similar movies to the user's input. The similarity is based on the Word2Vec vectors of the movie titles. The function then displays the top-k similar movie recommendations.
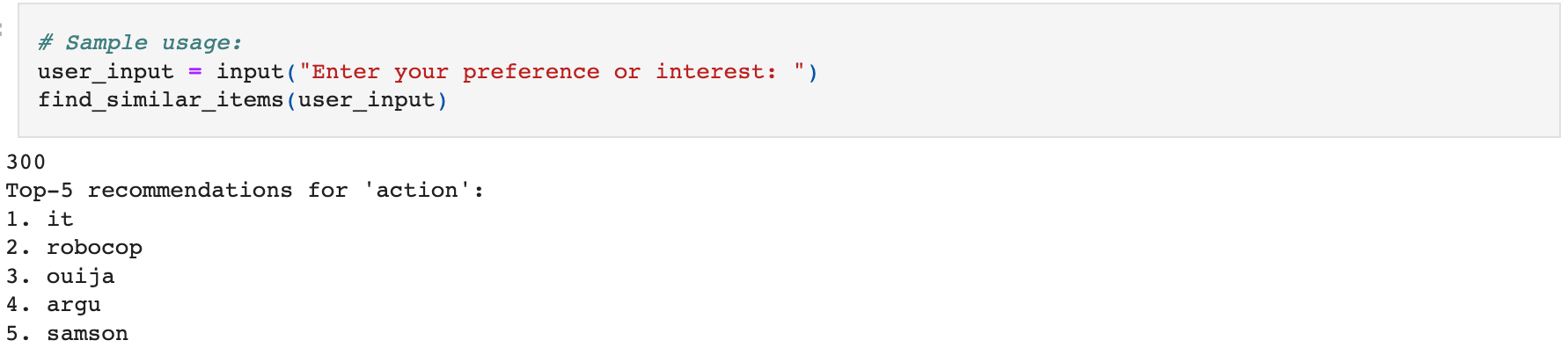
Sample Usage: The notebook provides sample usage examples to demonstrate how to use the recommendation system. It shows how to get recommendations for a general movie preference (using find_similar_items) and how to get personalized recommendations for a user (using get_user_recommendations) based on their liked movies.

Here’s the output for User 3:

Conclusion
In conclusion, vector databases have revolutionized data-driven decision making, as exemplified by our movie recommendation system. Leveraging Word2Vec embeddings and Faiss, we provided users with highly personalized movie suggestions. Across industries, vector databases drive revenue by delivering personalized experiences, detecting fraud, and optimizing decision-making. With their speed and accuracy, these databases unlock untapped potential in recommendation systems and data analysis. Embrace the vector database revolution for smarter decisions and unparalleled user experiences, propelling us towards a data-powered future. Let's continue pushing the boundaries of AI and ML together.
If you would like to kick the tires and take this sample code for a spin for a deeper look, you can clone the code in this blog from my Github repository.