



🚀 🔥 AI Medical Assistant Part 2: LLM and Chatbot Deployment
AI augmentation is set to reshape medical clinicians' roles, boosting efficiency and healthcare quality. - Contact info@mlpipes.xyz for more info

Introduction:
Let's revisit the key highlights from Part 1 of our journey. In our pursuit of optimizing training costs while aligning with smaller GPU instances, we meticulously configured a PEFT/LoRA model, implementing 4-bit quantization (QLoRA) through BitsAndBytesConfig. This strategic setup, executed prior to its utilization in the training script, effectively mitigated memory consumption during the training phase.
With the publicly available MedDialog dataset, the comprehensive fine-tuning endeavor demanded a total of 97 hours, spanning across 2 epochs, culminating in the convergence of the learning rate at 4.55e-8 and the training loss stabilizing at 1.71. The utilization of AWS SageMaker spot instances significantly reduced expenditure, albeit extending the training period due to intermittent interruptions, ultimately amounting to a remarkable 60% cost reduction, from an estimated $687.73 to $287.92. Notably, these insights underscore the intricate balance between time and expenditure.
Throughout this process, we harnessed the power of the W & B platform, seamlessly integrated with the wandb API within our training script, enabling us to diligently monitor our progress.
The overarching lesson derived from this phase is the pivotal trade-off between time efficiency and cost-effectiveness, particularly on larger GPU instances. It is noteworthy that our customized md-assistant model is readily accessible through MLPipes on the Hugging Face model hub, adhering to llama2 license terms.
Now, as we move forward armed with our finely-tuned model, we embark on the exciting journey of deploying it onto a production-grade AWS inference point and constructing a Streamlit Chatbot, serving as a Minimum Viable Product (MVP) User Interface. Furthermore, with the Chatbot in place, we gain the ability to rigorously assess the accuracy and relevance of our model's outputs. The next phase beckons with anticipation—let's proceed! 🚀
Deployment on AWS SageMaker:
The deployment process for our md-assistant model on AWS SageMaker exemplifies simplicity and efficiency. Leveraging the SageMaker platform, we establish an inference point with precision. This entails the creation of model and endpoint configurations, followed by the seamless deployment of our model into a Docker Container. Notably, we opted for Hugging Face DLC Containers, a strategic choice that aligns harmoniously with our model's architecture and encapsulates the essence of our project's versatility and extensibility. As in the fine-tuning stage, we use a 4 GPU instance (ml.g5.12xlarge) to host the inference point. Below, you will find an illustrative snippet that sheds light on the elegance and efficacy of this deployment process, a testament to the seamless fusion of cutting-edge AI technologies with SageMaker's robust infrastructure.
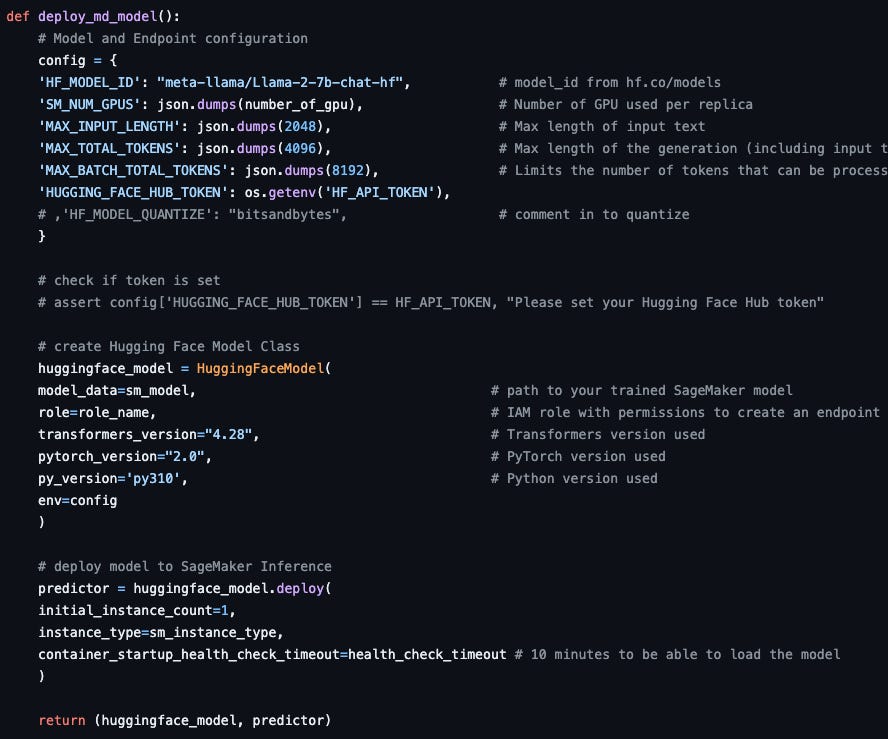
By returning the huggingface_model object in addition to the predictor object, we are able to delete and clean up these resources at a later time to avoid unnecessary inference hosting charges.
Configuring endpoints for real-time interaction
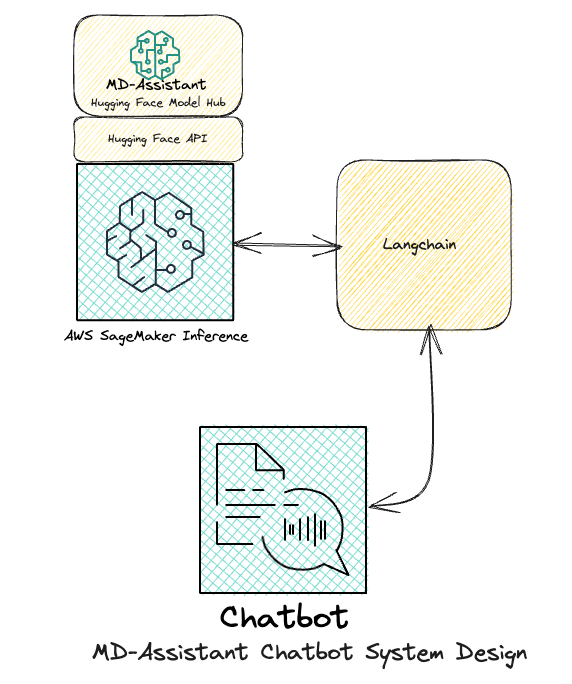
In the realm of a comprehensive production deployment, it is customary to establish a RESTful API endpoint, traditionally crafted using the Flask framework. This well-established practice is fortified with robust authentication and security measures, safeguarding the integrity of the system. However, within the context of our specific project, where the test client, embodied as the Streamlit Chatbot, operates from an AWS CLI-enabled local machine, we have chosen a streamlined approach. We have strategically implemented the Langchain LLM endpoint object, meticulously designed for SageMaker, and ingeniously integrated it within a ConversationChain object enriched with memory. This astute decision is a testament to our commitment to alignment with precise requirements and optimization for efficiency. While delving into the intricacies of Langchain implementation is beyond the scope of this discussion, a forthcoming blog may offer a comprehensive exploration of its integration within a Chatbot QA use-case. Below, you will find a code snippet that vividly exemplifies the elegance and efficiency inherent in our deployment strategy, highlighting its adaptability and versatility.
The Streamlit Chatbot
And within chat-md.py we access the endpoint through the ConversationChain…
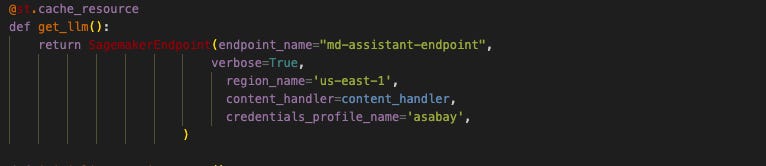
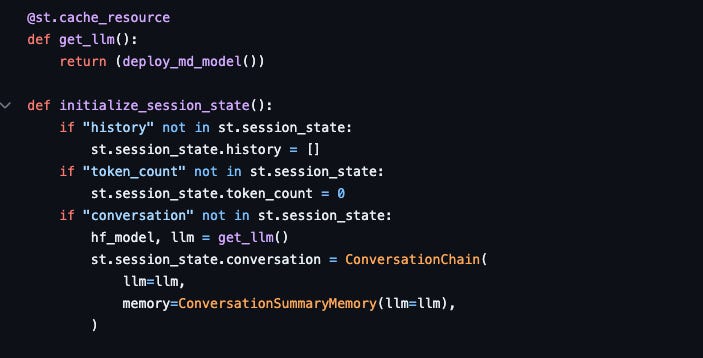
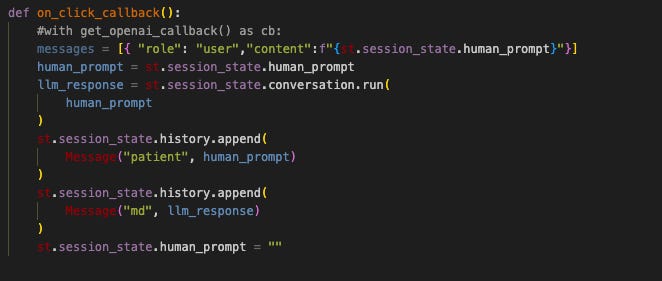
Upon user input into the chatbot, a pivotal event unfolds—the invocation of the on_click_callback() function. Within this function lies the core of our implementation, where we execute the ConversationChain object. This masterful orchestration involves processing the input text and summoning the deployed md-assistant to procure a precise and context-aware reply.
The default appearance of Streamlit's seemingly straightforward components left me yearning for more, prompting me to delve into the world of CSS customization to create a more aesthetically pleasing user interface. For an in-depth exploration of this customization process, I recommend perusing Fanilo Andrianasolo's GitHub repository, which offers valuable insights into this artful endeavor. Additionally, you can find the chatbot's code within the Chatbot folder on my GitHub repository dedicated to this project, providing a comprehensive resource for those seeking further details and inspiration.
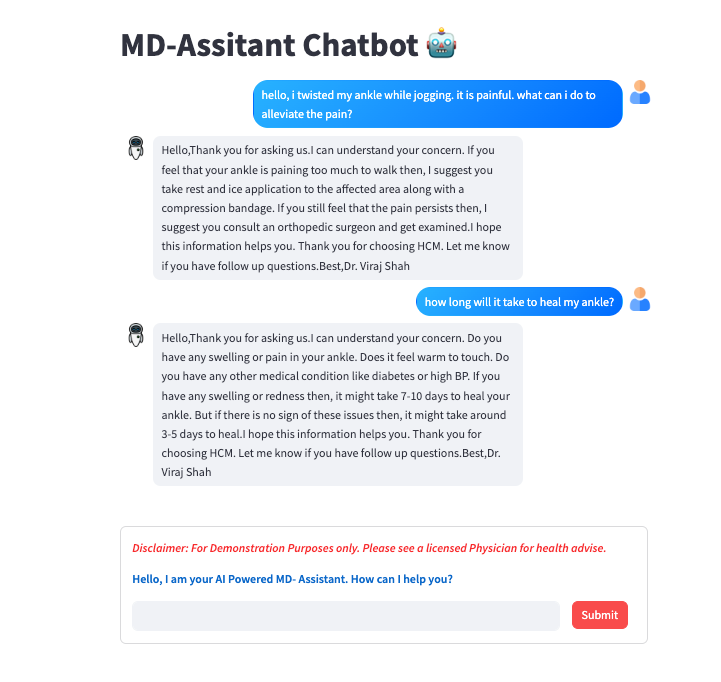
Here’s a screen recording of the md-assistant chatbot in operation 🤓
Model Performance Evaluation:
Given the fine-tuned nature of the md-assistant model to cater specifically to clinician-to-patient dialogues, our testing protocol entails the rigorous examination of simulated user inputs that have never previously crossed paths with the md-assistant model. This meticulous approach is indispensable for assessing accuracy and contextual relevance. In my comprehensive testing endeavor, I subjected the model to 100 out-of-bag questions, and the results unequivocally showcased responses that remained impeccably contextual and entirely pertinent to the addressed topics. Moreover, the model's versatility was evident as it responded to the same questions with slight variations, preserving context, thanks to the 'repetition_penalty' setting of 1.03 and a 'temperature' value of 0.7. However, it is essential to emphasize that the true accuracy of the llm response can only be comprehensively evaluated by licensed medical clinicians—a step we have yet to undertake.
In a real-world, commercially deployed application of the md-assistant llm model, a critical phase would encompass Subject Matter Expert (SME) evaluation, instrumental for model testing and validation. Furthermore, standard operating procedure for deploying a fine-tuned chat model like this involves an exhaustive scrutiny of dialog and meticulous data anonymization, ensuring compliance with the stringent requirements of HIPAA. In such scenarios, the model can be further fine-tuned to align precisely with a specific clinician's advisory history, a departure from the MedDialog public dataset, which encompasses a vast array of over 250,000 utterances, spanning 51 medical categories and 96 specialties, from diverse patients and medical professionals.
Conclusion and Key Takeaways
Our journey, spanning both fine-tuning and deployment stages, has uncovered several key insights and achievements:
1. Optimized Training: We diligently tailored our PEFT/LoRA model, implementing 4-bit quantization (QLoRA) through BitsAndBytesConfig, successfully mitigating memory consumption during training—a crucial step towards cost-effective GPU utilization.
2. Efficiency vs. Cost: Balancing time efficiency and cost-effectiveness in GPU instance selection was paramount. Utilizing AWS SageMaker spot instances achieved a remarkable 60% cost reduction, albeit with extended training periods.
3. Monitoring with W & B: Our integration of the W & B platform and wandb API provided invaluable progress monitoring, ensuring fine-tuning precision.
4. Deployment Excellence: Deploying on AWS SageMaker was a seamless process, with Docker Container utilization, highlighting our strategic choice of Hugging Face DLC Containers for compatibility and adaptability.
5. Real-time Interaction: Implementing Langchain LLM endpoints within a ConversationChain object, a deviation from traditional RESTful API approaches, showcased our commitment to tailored efficiency.
6. UI Customization: We delved into CSS customization to enhance the Streamlit Chatbot's user interface, offering an improved user experience.
7. Model Testing: Rigorous testing of the fine-tuned model with simulated user inputs revealed contextually precise responses. Repetition_penalty settings allowed for nuanced variations, emphasizing adaptability.
8. SME Evaluation: In a real-world, commercial deployment, Subject Matter Expert (SME) evaluation and HIPAA-compliant data anonymization would be pivotal, showcasing the model's flexibility in adapting to specific clinician advisory histories.
In essence, our journey underscores the fusion of cutting-edge AI technologies with efficient deployment strategies and meticulous model testing. While we've made significant strides, the path ahead holds exciting possibilities as we continue to refine and adapt our md-assistant LLM model to the dynamic field of clinician-patient interactions.
Project Demo:
If you're eager to witness a live demonstration of our end-to-end Chatbot application in action, don't hesitate to reach out to me directly at MLPipes. I'd be delighted to schedule a convenient time to showcase the demo. While we're unable to maintain a live deployment of the model due to GPU hosting costs, you can alternatively engage with me via the MLPipes Chatbot.
Should you have a specific LLM Customization project in mind and seek to explore possibilities, I encourage you to initiate contact with me at MLPipes. I'm more than willing to engage in a productive discussion about your project needs. At MLPipes, our expertise lies in Machine Learning Engineering and LLM Customization, and we're eager to collaborate on your next endeavor. 🚀
For those who found value in this blog, we extend an invitation to seize the opportunity for a complimentary subscription below.
References:
Sam Rawal: Llama2 Chat Templater
Fanilo Andrianasolo: Social Media Tutorials Github - Fantastic examples on how to add css to Streamlit!!
Alfeo Sabay: MD Assistant Github
Alfeo Sabay: MLPipes Hugging Face Model Hub - Where you can access this fantastic model!! 💪🚀😁